
Automatic Speech Recognition with Synthetic Speech
This project investigates a pivotal challenge impeding the progress of cutting-edge speech recognition technology—the procurement of high-quality data. It examines the potential of synthetic speech generation to eliminate the exorbitant expenses involved in gathering necessary data. Specifically, the project evaluates whether a speech recognition system trained exclusively on synthetic speech can rival the performance of one trained on genuine human speech.
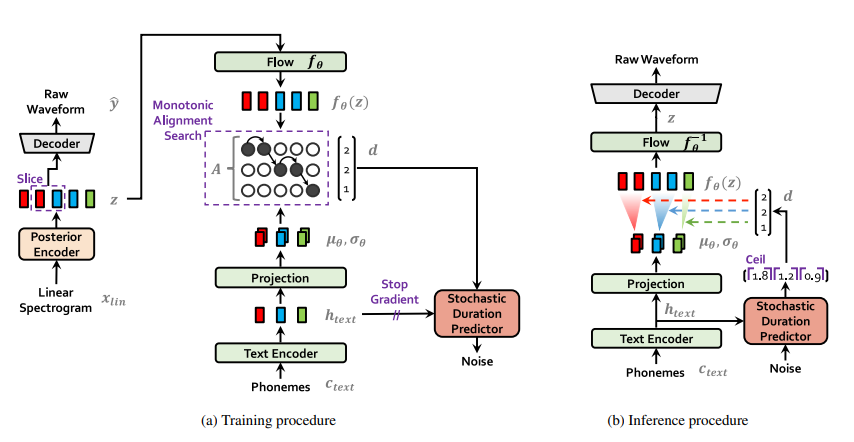
This project addressed the significant challenge in the advancement of high-caliber automatic speech recognition systems: the procurement of well-labeled and carefully curated data, which has been historically costly in terms of both time and financial resources. The aim was to determine whether speech recognition systems trained entirely on synthetic speech could equal or exceed the performance of those trained on real human speech. The project conducted a thorough examination of speech synthesizers to pinpoint the most efficient techniques to create a synthetic speech corpus capable of competing with the quality of real human speech in training applications.
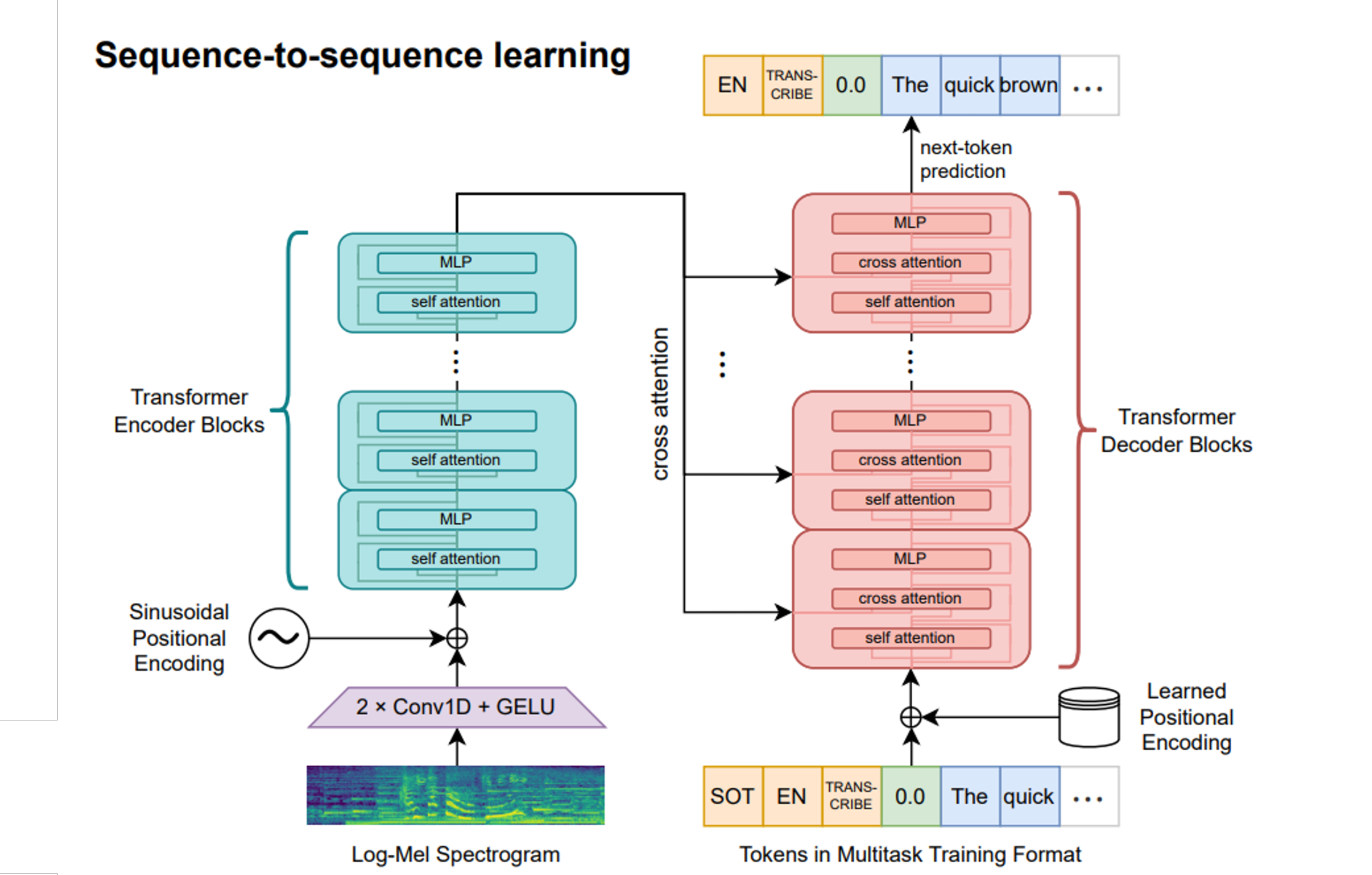
The study investigated whether speech recognition systems trained solely on synthetic speech were able to generalize and function effectively in real-world conditions. The confirmation of this effectiveness could signal a significant shift in the field of speech technology research, underscoring the critical role of accurate speech synthesis. Improvements in synthetic speech technology might negate the substantial costs associated with data gathering and curation, redirecting resources toward the enhancement of both synthesis and recognition system development and training.
As a part of this project I used Machine Learning techniques like SVM, ANNs, and Random Forests to forecast the effect of Greenhouse Gas emissions on air quality in Pittsburgh. As mentoned before the core idea was to predict how local temperatures are affected by global gas emissions, and these predictions from one model (eg. SVM) were compared with other models (eg. ANNs and SVM). Moreover, We performed two experiments to test the accuracy of our model.For the first approach we used a sliding window which was used to directly predict future values. Second, the predicted temperature values are appended back to the dataset and are utilized for future predictions. However, we noticed that predicting the future beyond the available data led to innacurate results and concluded our appraoch was not enough. A second approach was developed where for predicting the future beyond the available data requires adding the prediction back to the data and predicting based on the new data. Surprisingly, we observed our predictions were distinctly wrong. For SVM/SVR we found the Mean Absolute Percentage Error for the first approach to be around 7.32%. For the second approach, we found the Mean Absolute Percentage Error to be very large around 37.77 %. Next for Random Forest, the testing gave us 7.56% Mean Absolute Percentage Error, and the test on the data by adding the prediction back to the dataset to predict gave us 15.69% Mean Absolute Percentage Error. In contradiction to our expectations, using Artificial Neural Networks showed worse performance.
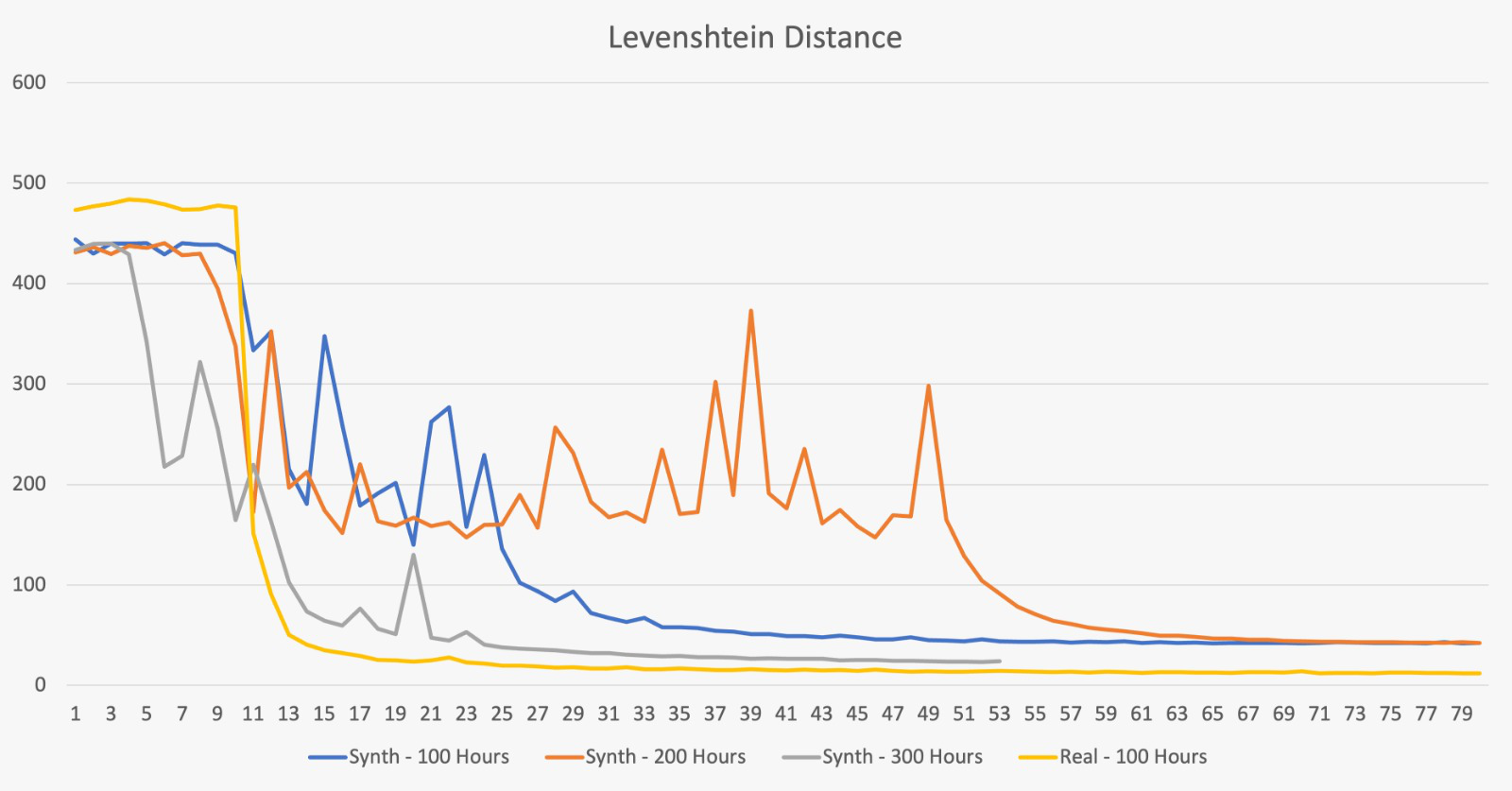
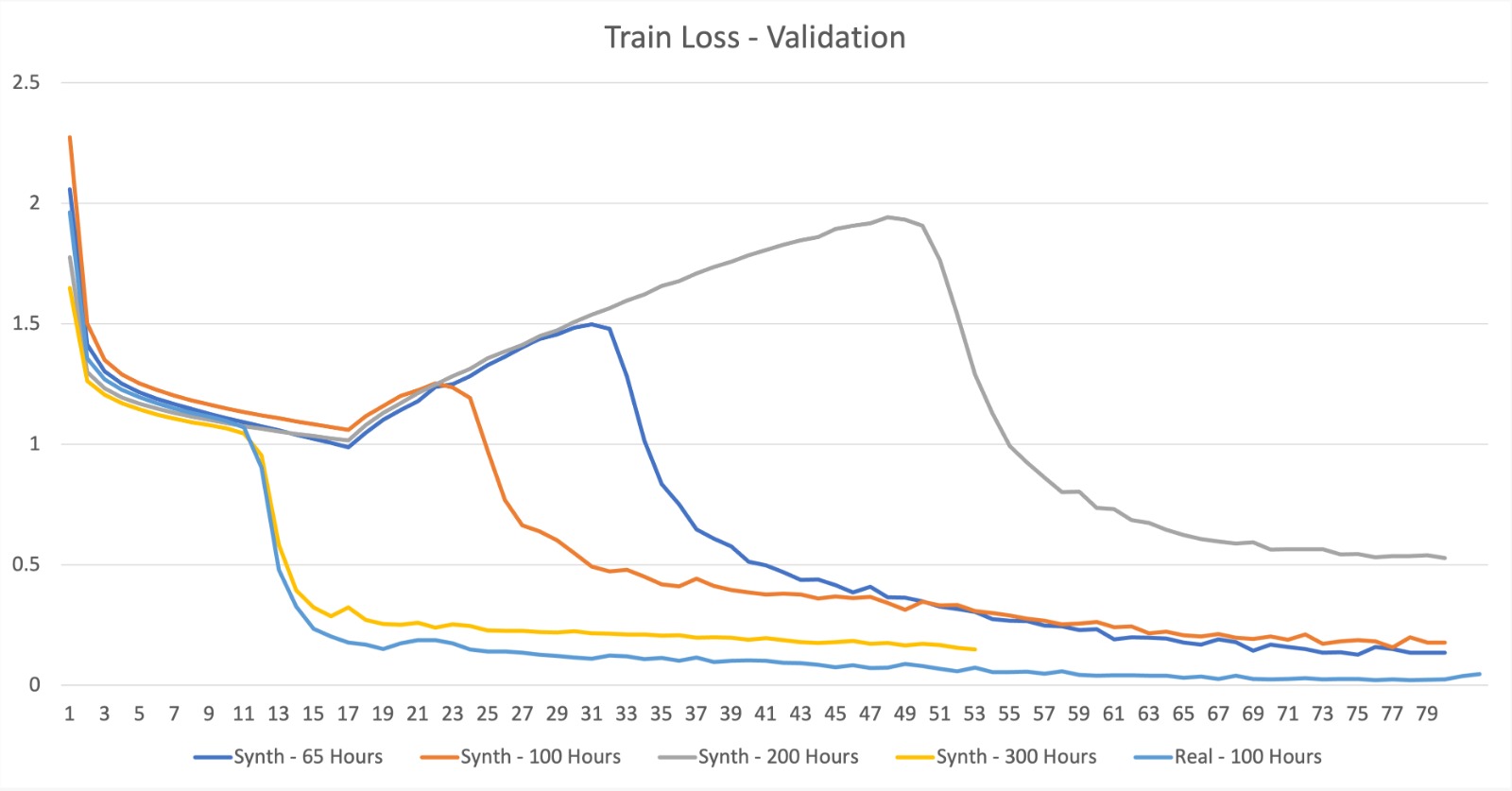
In the next phase of our automated speech recognition system’s development, we plan to implement a pre-trained speech synthesizer based on the Vall-E architecture. This synthesizer will be instrumental in generating a substantial volume of synthetic speech, which will be used to enhance our current training dataset, thereby improving the accuracy and robustness of our system. To ensure a wide variety of generated data, we will apply several augmentation techniques, such as pitch shifting, noise addition, speech speed perturbation, and time stretching. These methods will introduce necessary variability into our training data, which is crucial for the system to accurately recognize diverse speaking styles and accents.
Our goal is to reach unparalleled accuracy levels by training OpenAI’s Whisper model from the ground up, using the enriched dataset produced by our speech synthesizer. This strategy is designed to tackle specific challenges encountered in speech recognition, including background noise, variation in speech rates, and differences in speaker characteristics.
To summarize, our strategy involves integrating a sophisticated speech synthesizer with advanced augmentation techniques to expand the diversity and volume of our training data. This method is expected to significantly contribute to our overarching objective of creating an exceptionally precise and resilient automated speech recognition system.